(1) Información redundante do sinal de vídeo
Tomando como exemplo o formato compoñente YUV de gravación de vídeo dixital, YUV representa sinais de brillo e dúas diferenzas de cor respectivamente. Por exemplo, para o sistema de TV pal existente, a frecuencia de mostraxe do sinal de luminancia é de 13.5 MHz; a banda de frecuencia do sinal de croma adoita ser a metade ou menos do sinal de brillo, que é de 6.75 MHz ou 3.375 MHz. Tomando como exemplo a frecuencia de mostraxe de 4: 2: 2, o sinal Y adopta 13.5 mhz, o sinal de croma U e V é mostrado en 6.75 MHz e o sinal de mostraxe cuantifícase en 8 bits, entón pódese calcular a taxa de código do vídeo dixital como segue:
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216Mbit / s
Se unha cantidade tan grande de datos se almacena ou transmite directamente, será difícil utilizar a tecnoloxía de compresión para reducir a taxa de bits. O sinal de vídeo dixital pódese comprimir segundo dúas condicións básicas:
L. redundancia de datos. Por exemplo, redundancia espacial, redundancia de tempo, redundancia de estrutura, redundancia de entropía de información, etc., é dicir, hai unha forte correlación entre os píxeles da imaxe. Eliminar esta redundancia non leva á perda de información e é a compresión sen perdas.
L. redundancia visual. Algunhas características dos ollos humanos, como o limiar de discriminación de brillo, o limiar visual, son diferentes na sensibilidade ao brillo e ao croma, o que fai imposible introducir erros adecuados na codificación e non se detectarán. As características visuais dos ollos humanos pódense usar para intercambiar compresión de datos con certa distorsión obxectiva. Esta compresión é con perdas.
A compresión do sinal de vídeo dixital baséase nas dúas condicións anteriores, o que fai que os datos de vídeo sexan moi comprimidos, o que favorece a transmisión e almacenamento. Os métodos comúns de compresión de vídeo dixital son a codificación mixta, que consiste en combinar codificación de transformadas, estimación de movemento e compensación de movemento e codificación de entropía para comprimir a codificación. Normalmente, a codificación de transformación úsase para eliminar a redundancia intra fotograma da imaxe, e a estimación do movemento e a compensación de movemento úsanse para eliminar a redundancia entre fotogramas da imaxe e a codificación de entropía úsase para mellorar aínda máis a eficiencia de compresión. Os tres seguintes métodos de codificación por compresión introdúcense brevemente.
(a) Método de codificación por compresión
(b) Transformar a codificación
A función da codificación de transformación é transformar o sinal de imaxe descrito no dominio espacial ao dominio de frecuencia e logo codificar os coeficientes transformados. En xeral, a imaxe ten unha forte correlación no espazo e a transformación en dominio de frecuencia pode producir descorrelación e concentración de enerxía. A transformada ortogonal común inclúe a transformada de Fourier discreta, a transformada discreta de coseno, etc. A transformación de coseno discreto úsase amplamente na compresión de vídeo dixital.
A transformada discreta do coseno chámase transformada DCT. Pode transformar o bloque de imaxes de L * l de dominio espacial a dominio de frecuencia. Polo tanto, no proceso de compresión e codificación de imaxes baseado en DCT, a imaxe debe dividirse en bloques de imaxes non superpostos. Supoñamos que o tamaño dunha imaxe é de 1280 * 720, está dividido en bloques de imaxes de 160 * 90 con tamaño de 8 * 8 sen superposición en forma de cuadrícula. Despois pódese realizar a transformación DCT para cada bloque de imaxe.
Despois de dividir o bloque, cada bloque de imaxe de 8 * 8 puntos envíase ao codificador DCT e o bloque de imaxe 8 * 8 transfórmase do dominio espacial ao dominio de frecuencia. A figura seguinte mostra un exemplo dun bloque de imaxes de 8 * 8 no que o número representa o valor de brillo de cada píxel. Pola figura pódese ver que os valores de brillo de cada píxel deste bloque de imaxe son relativamente uniformes, especialmente o valor de brillo dos píxeles adxacentes non é moi grande, o que indica que o sinal da imaxe ten unha forte correlación.
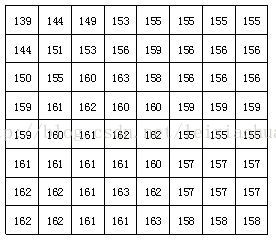
Un bloque de imaxe real de 8 * 8
A seguinte figura mostra os resultados da transformación DCT do bloque de imaxe na figura anterior. Pola figura pódese ver que despois da transformación DCT, o coeficiente de baixa frecuencia na esquina superior esquerda concentra moita enerxía, mentres que a enerxía do coeficiente de alta frecuencia na esquina inferior dereita é moi pequena.
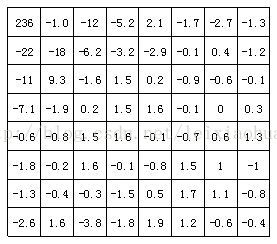
Os coeficientes do bloque de imaxe despois da transformación DCT
O sinal debe ser cuantificado despois da transformación DCT. Debido a que os ollos humanos son sensibles ás características de baixa frecuencia das imaxes, como o brillo xeral dos obxectos, e non aos detalles de alta frecuencia da imaxe, polo que no proceso de transmisión a información de alta frecuencia pódese transmitir menos ou menos, só a parte de baixa frecuencia. O proceso de cuantificación reduce a transmisión de información ao cuantificar os coeficientes da rexión de baixa frecuencia e a cuantificación grosa dos coeficientes na rexión de alta frecuencia, o que elimina a información de alta frecuencia que non é sensible aos ollos humanos. Polo tanto, a cuantificación é un proceso de compresión con perdas e o principal motivo do dano á calidade na codificación por compresión de vídeo.
O proceso de cuantificación pódese expresar coa seguinte fórmula:

Entre eles, FQ (U, V) representa o coeficiente DCT despois da cuantificación; f (U, V) representa o coeficiente DCT antes da cuantificación; Q (U, V) representa a matriz de ponderación de cuantización; q é o paso de cuantificación; round fai referencia á consolidación e o valor a producir tómase como o valor enteiro máis próximo.
Seleccione o coeficiente de cuantificación razoablemente e o resultado despois de cuantificar o bloque de imaxe transformado móstrase na figura.

Coeficiente DCT despois da cuantificación
A maioría dos coeficientes DCT cambian a 0 despois da cuantificación, mentres que só algúns coeficientes son valores distintos de cero. Neste momento, só estes valores diferentes a cero precisan ser comprimidos e codificados.
(b) Codificación de entropía
A codificación de entropía denomínase porque a lonxitude media do código despois da codificación é próxima ao valor de entropía da fonte. A codificación de entropía está implementada por VLC (codificación de lonxitude variable). O principio básico é dar código curto ao símbolo con alta probabilidade na fonte e dar código longo ao símbolo con pouca probabilidade de aparición, de xeito que se obteña a lonxitude media do código máis curta estatisticamente. A codificación de lonxitude variable normalmente inclúe código Hoffman, código aritmético, código de execución, etc. A codificación de lonxitude de execución é un método de compresión moi sinxelo, a súa eficiencia de compresión non é alta, pero a velocidade de codificación e decodificación é rápida e aínda se usa moito, especialmente despois da transformación da codificación, usando a codificación de lonxitude de execución, ten un bo efecto.
En primeiro lugar, o coeficiente de CA inmediatamente despois do coeficiente de saída DC do cuantificador escanearase en tipo Z (como se mostra na liña de frecha). A exploración en Z transforma o coeficiente de cuantificación bidimensional en secuencia unidimensional e despois continúa a codificación da lonxitude de execución. Finalmente, úsase outro código de lonxitude variable para codificar os datos despois da codificación de execución, como a codificación Hoffman. A través deste tipo de codificación de lonxitude variable, a eficiencia da codificación mellora aínda máis.
(c) Estimación do movemento e compensación do movemento
A estimación do movemento e a compensación do movemento son métodos eficaces para eliminar a correlación da dirección do tempo das secuencias de imaxes. Os métodos de transformación, cuantificación e codificación de entropía DCT descritos anteriormente baséanse nunha imaxe de cadro. A través destes métodos pódese eliminar a correlación espacial entre píxeles da imaxe. De feito, ademais da correlación espacial, o sinal de imaxe ten correlación temporal. Por exemplo, para o vídeo dixital con fondo estático como a transmisión de noticias e un pequeno movemento do corpo principal da imaxe, a diferenza entre cada imaxe é moi pequena e a correlación entre imaxes é moi grande. Neste caso, non precisamos codificar cada imaxe de cadro por separado, senón que só podemos codificar as partes cambiadas de cadros de vídeo adxacentes, para reducir aínda máis a cantidade de datos. Este traballo realízase mediante a estimación do movemento e a compensación do movemento.
A tecnoloxía de estimación de movemento xeralmente divide a imaxe de entrada actual en varios pequenos sub bloques de imaxe que non se superpoñen entre si, por exemplo, o tamaño dunha imaxe de cadro é 1280 * 720. En primeiro lugar, divídese en 40 * 45 bloques de imaxe con 16 * 16 tamaño que non se superpoñen entre si en forma de cuadrícula e logo, dentro do ámbito dunha xanela de busca da imaxe anterior ou da última imaxe, atope un bloque para cada bloque de imaxe para atopar un bloque de imaxe dentro do ámbito dun xanela de busca O bloque de imaxes máis semellante. O proceso de busca chámase estimación do movemento. Ao calcular a información de posición entre o bloque de imaxe máis similar e o bloque de imaxe, pódese obter un vector de movemento. Deste xeito, pódese restar o bloque de imaxe actual do bloque de imaxe máis similar apuntado polo vector de movemento de imaxe de referencia e pódese obter un bloque de imaxe residual. Debido a que cada valor de píxel no bloque de imaxe residual é moi pequeno, pódese obter unha maior relación de compresión na codificación de compresión. Este proceso de resta chámase compensación de movemento.
Debido a que a imaxe de referencia é necesaria para a estimación do movemento e a compensación do movemento no proceso de codificación, é moi importante seleccionar a imaxe de referencia. Xeralmente, o codificador divide cada entrada de imaxe de cadro en tres tipos diferentes segundo as diferentes imaxes de referencia: marco I (intra), marco B (predición de guía) e marco P (predición). Como se mostra na figura.
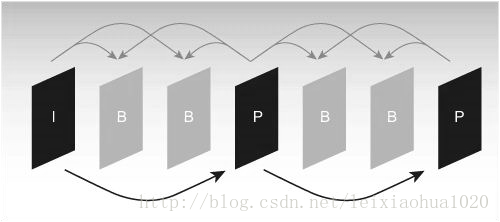
Secuencia típica de estrutura de cadros I, B, P
Como se mostra na figura, o fotograma I só usa os datos do fotograma para codificar e non precisa estimación de movemento e compensación de movemento durante o proceso de codificación. Obviamente, dado que o marco non elimina a correlación da dirección do tempo, a relación de compresión é relativamente baixa. No proceso de codificación, o marco P utiliza un marco frontal I ou marco P como imaxe de referencia para a compensación do movemento, de feito, codifica a diferenza entre a imaxe actual e a imaxe de referencia. O modo de codificación do cadro B é similar ao cadro P, a única diferenza é que precisa usar un cadro I frontal ou cadro P e un cadro I ou cadro P posterior para predicir durante o proceso de codificación. Así, cada codificación de fotogramas P necesita usar unha imaxe de fotograma como imaxe de referencia, mentres que o fotograma B precisa de dous fotogramas como referencia. Pola contra, o cadro B ten unha relación de compresión máis alta que o cadro P.
(d) Codificación mixta
O artigo introduce varios métodos importantes na compresión e codificación de vídeo. Na aplicación práctica, estes métodos non están separados e normalmente combínanse para lograr o mellor efecto de compresión. A seguinte figura mostra o modelo de codificación híbrida (é dicir, codificación de transformadas + estimación de movemento e compensación de movemento + codificación de entropía). O modelo é amplamente utilizado en MPEG1, MPEG2, H.264 e outros estándares. Dende a figura, podemos ver que a imaxe de entrada actual debe dividirse primeiro en bloques, o bloque da imaxe obtida polo bloque restarase da imaxe prevista despois da compensación do movemento para obter a diferenza de imaxe x, e logo realízase a transformación e cuantificación DCT para o bloque de imaxe de diferenza. Os datos de saída cuantificados teñen dous lugares diferentes: un é envialos ao codificador de entropía para codificar e o fluxo de código codificado é emitido a unha caché Gardar no dispositivo e agardar a transmisión. Outra aplicación é contrarrestar a cuantificación e inverter o cambio ao sinal x ', que engade a saída do bloque de imaxe con compensación de movemento para obter un novo sinal de imaxe de predición e envía un novo bloque de imaxe de predición á memoria de cadros.



|
|
|
|
Como distante (long) a tapa do transmisor?
A franxa de transmisión depende de moitos factores. A distancia real baséase na altura da antena de instalar, a ganancia da antena, usando ambiente como a construción e outras obturacións, a sensibilidade do receptor, a antena do receptor. Instalación de antena máis alta e usando o campo, a distancia vai moito máis lonxe.
EXEMPLO 5W FM Transmitter usar na cidade e cidade natal:
Teño un uso do cliente 5W transmisor FM EUA con antena GP na súa cidade natal, e proba-lo con un coche, cubrir 10km (6.21mile).
I probar o transmisor FM 5W con antena GP na miña cidade natal, que cobren aproximadamente 2km (1.24mile).
I probar o transmisor FM 5W con antena GP na cidade de Guangzhou, que abranguen aproximadamente única 300meter (984ft).
Abaixo amósanse ao descanso aproximado de diferentes transmisores de enerxía FM. (O intervalo é de diámetro)
0.1W ~ 5W Transmisor FM: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W Transmisor FM: 3KM ~ 10KM
80W ~ 500W Transmisor FM: 10KM ~ 30KM
500W ~ 1000W Transmisor FM: 30KM ~ 50KM
1KW ~ 2KW Transmisor FM: 50KM ~ 100KM
2KW ~ 5KW Transmisor FM: 100KM ~ 150KM
5KW ~ 10KW Transmisor FM: 150KM ~ 200KM
Como contactar connosco para o transmisor?
Chama-me + 8618078869184 OU
Enviar email me [protexido por correo electrónico]
1.How lonxe quere cubrir de diámetro?
2.How altura de torre ti?
3.Where es?
E imos dar-lle consellos máis profesional.
Sobre nós
FMUSER.ORG é unha empresa de integración de sistemas centrada en equipos de transmisión / transmisión de audio sen fíos de radio / estudio de vídeo e procesamento de datos. Estamos ofrecendo todo desde asesoramento e consultoría a través da integración de rack ata a instalación, posta en servizo e adestramento.
Ofrecemos transmisor de FM, transmisor de TV analóxico, transmisor de TV dixital, transmisor UHF de VHF, antenas, conectores de cable coaxial, STL, procesamento de aire, produtos de transmisión para o estudio, monitorización de sinais de RF, codificadores de RDS, procesadores de audio e unidades de control de sitios remotos. Produtos IPTV, codificador / decodificador de audio / vídeo, deseñados para satisfacer as necesidades de grandes redes de transmisión internacionais e pequenas estacións privadas.
A nosa solución ten estación de radio FM / estación de televisión analóxica / estación de TV dixital / equipos de estudio de vídeo e vídeo / enlace de transmisión de estudio / sistema de telemetría de transmisor / sistema de TV de hotel / transmisión en directo IPTV / transmisión en directo de transmisión / conferencia de vídeo / sistema de transmisión CATV.
Estamos a usar produtos de tecnoloxía avanzada para todos os sistemas, porque sabemos que a alta fiabilidade e alto rendemento son tan importantes para o sistema e a solución. Ao mesmo tempo, temos que asegurarnos que o noso sistema de produtos a un prezo moi razoable.
Temos clientes de radiodifusores públicos e comerciais, operadores de telecomunicacións e autoridades reguladoras, e tamén ofrecemos solucións e produtos a moitos centos de emisoras locais e comunitarias máis pequenas.
FMUSER.ORG leva máis de 15 anos exportando e ten clientes en todo o mundo. Con 13 anos de experiencia neste campo, temos un equipo profesional para resolver todo tipo de problemas do cliente. Dedicámonos a ofrecer prezos extremadamente razoables de produtos e servizos profesionais. Correo electrónico de contacto: [protexido por correo electrónico]
nosa fábrica

Temos modernización da fábrica. Estás convidado a visitar a nosa fábrica cando chegar a China.

Actualmente, xa existen clientes 1095 en todo o mundo visitan nosa oficina Guangzhou Tianhe. Se ve a China, está invitado a visitar-nos.
na Feira

Esta é a nosa participación en 2012 Global Sources Hong Kong Fair Electrónica . Clientes de todo o mundo finalmente ter a oportunidade de estar xuntos.
Onde está Fmuser?
Podes buscar nestes números " 23.127460034623816,113.33224654197693 "en google map, entón podes atopar a nosa oficina fmuser.
oficina FMUSER Guangzhou está Tianhe District, que é a centro do cantón . moi preto ao Feira de Cantón , Estación ferroviaria Guangzhou, estrada Xiaobei e dashatou , Só ten minutos 10 tomar TAXI . Benvidos amigos de todo o mundo a visitar e negociar.
Contacto: Ceo azul
Móbil: + 8618078869184
WhatsApp: + 8618078869184
Wechat: + 8618078869184
E-mail: [protexido por correo electrónico]
QQ: 727926717
Skype: sky198710021
Dirección: No.305 cuarto Huilan Edificio No.273 Huanpu Estrada Guangzhou China Zip: 510620
|
|
|
|
Inglés: Aceptamos todos os pagos, como PayPal, tarxeta de crédito, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, Se tes algunha pregunta, póñase en contacto comigo [protexido por correo electrónico] ou WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Recomendamos que use Paypal para mercar os nosos produtos, PayPal é unha forma segura de mercar en internet.
Cada da nosa lista de elementos de páxina de fondo na parte superior ten un logotipo PayPal para pagar.
Tarxeta de crédito.Se non ten paypal, pero ten tarxeta de crédito, tamén se pode facer clic no botón amarelo PayPal para pagar coa súa tarxeta de crédito.
-------------------------------------------------- -------------------
Pero se non ten unha tarxeta de crédito e non ten unha conta PayPal ou de difícil ten un accout PayPal, pode utilizar o seguinte:
Western Union.  www.westernunion.com www.westernunion.com
Pago por Western Union para min:
Nome / nome: Yingfeng
Apelido / Apelido / Apelido: Zhang
Nome completo: Yingfeng Zhang
País: China
Cidade: Guangzhou
|
-------------------------------------------------- -------------------
T / T. pago por T / T (transferencia bancaria / transferencia telegráfica / Transferencia bancaria)
Primeira información bancaria (conta da empresa):
SWIFT BIC: BKCHHKHHXXX
Nome do banco: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Enderezo bancario: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
CÓDIGO BANCO: 012
Nome da conta: FMUSER INTERNATIONAL GROUP LIMITED
Conta NON. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Segunda INFORMACIÓN BANCARIA (CONTA DA EMPRESA):
Beneficiario: Fmuser International Group Inc.
Número de conta: 44050158090900000337
Banco do beneficiario: China Construction Bank Sucursal de Guangdong
Código SWIFT: PCBCCNBJGDX
Enderezo: estrada Tianhe NO.553, Cantón, Guangdong, distrito de Tianhe, China
** Nota: cando transfira cartos á nosa conta bancaria, NON escriba nada na área de comentarios, se non, non poderemos recibir o pago debido á política gobernamental sobre o comercio internacional.
|
|
|
|
* Será enviado en 1 2 día de traballo cando o pagamento clara.
* Nós imos envialo seu enderezo de paypal. Se queres cambiar de dirección, por favor, envíe o seu enderezo correcto e número de teléfono para o meu e-mail [protexido por correo electrónico]
* Se os paquetes está baixo 2kg, que serán enviados vía correo aéreo, vai levar preto de 15-25days para a súa man.
Se o paquete é máis que 2kg, nós enviamos vía EMS, DHL, UPS, FedEx entrega rápida expresa, vai levar preto de 7 ~ 15days para a súa man.
Se o paquete de máis de 100kg, enviarémoslle vía DHL ou transporte aéreo. Isto levará uns 3 ~ 7days para a súa man.
Todos os paquetes son a forma China Guangzhou.
* O paquete enviarase como un "agasallo" e descartarase o menos posible, o comprador non terá que pagar o "IMPOSTO".
* Despois de navío, nós enviarémosche un correo electrónico e darlle o número de rastreamento.
|
|
|
Para garantía.
Contacte connosco --- >> Devólvenos o artigo --- >> Reciba e envíe outro substituto.
Nome: Liu Xiaoxia
Dirección: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou China.
CEP: 510620
Teléfono: + 8618078869184
Por favor, retorne a este enderezo e escribir o seu paypal enderezo, nome, problema na nota: |
|













