Cando empregamos ferramentas como Skype e QQ para realizar conversas de voz e vídeo sen problemas cos amigos, ¿preguntámonos algunha vez que tecnoloxías poderosas hai detrás? Este artigo dará unha breve introdución ás tecnoloxías empregadas nas chamadas de voz en rede, que se poden considerar como unha ollada ao leopardo.
1. Modelo conceptual
As chamadas de voz por Internet adoitan ser bidireccionais, o que é simétrico a nivel de modelo. Por motivos de simplicidade, podemos discutir a canle nunha dirección. Unha das partes fala e a outra escoita a voz. Parece sinxelo e rápido, pero o proceso detrás é bastante complicado.
Este é o modelo máis básico composto por cinco enlaces importantes: adquisición, codificación, transmisión, decodificación e reprodución.
(1) Colección de voz
A recollida de voz refírese á recollida de datos de audio dun micrófono, é dicir, a conversión de mostras de son en sinais dixitais. Implica varios parámetros importantes: frecuencia de mostraxe, número de bits de mostraxe e número de canles.
En poucas palabras: a frecuencia de mostraxe é o número de accións de adquisición en 1 segundo; o número de bits de mostraxe é a lonxitude dos datos obtidos para cada acción de adquisición.
O tamaño dun marco de audio é igual a: (frecuencia de mostraxe × número de bits de mostraxe × número de canles × tempo)
Normalmente, a duración dun marco de mostraxe é de 10 ms, é dicir, cada 10 ms de datos constitúe un marco de audio. Supoñendo: a taxa de mostraxe é de 16 k, o número de bits de mostraxe é de 16 bits e o número de canles é 1, entón o tamaño dun marco de audio de 10 ms é: (16000 * 16 * 1 * 0.01) / 8 = 320 bytes. Na fórmula de cálculo, 0.01 é un segundo, é dicir, 10 ms.
(2) Codificación
Supoñendo que enviamos o marco de audio recollido directamente sen codificación, podemos calcular o requisito de ancho de banda requirido. Aínda así o exemplo anterior: 320 * 100 = 32KBytes / s, se se converte en bits / s, é de 256kb / s. Este é un bo uso de ancho de banda. Coas ferramentas de control de tráfico de rede, podemos descubrir que cando as chamadas de voz se realizan con software de mensaxería instantánea como QQ, o tráfico é de 3-5 KB / s, que é unha orde de magnitude menor que o tráfico orixinal. Isto débese principalmente á tecnoloxía de codificación de audio. Polo tanto, na aplicación de chamada de voz real, esta ligazón de codificación é indispensable. Hai moitas tecnoloxías de codificación de voz de uso común, como G.729, iLBC, AAC, SPEEX, etc.
(3) Transmisión de rede
Cando se codifica un marco de audio, pódese enviar ao interlocutor a través da rede. Para aplicacións en tempo real como conversas de voz, a baixa latencia e estabilidade son moi importantes, o que require que a nosa rede transmita de forma moi fluída.
(4) Descodificación
Cando a outra parte reciba o cadro codificado, descodificalo para restauralo en datos que a tarxeta de son pode reproducir directamente.
(5) Reprodución de voz
Despois de completar a descodificación, o cadro de audio obtido pode enviarse á tarxeta de son para a súa reprodución. Anexo: pode consultar a introdución e o código fonte de demostración e a descarga do SDK de MPlayer, un compoñente de reprodución de voz
2. Dificultades e solucións en aplicacións prácticas
Se só confiar na tecnoloxía mencionada pode realizar un sistema de diálogo sólido aplicado á rede de área ampla, non hai moita necesidade de escribir este artigo. É precisamente que moitos factores realistas introduciron moitos desafíos para o modelo conceptual mencionado, o que fai que a realización do sistema de voz en rede non sexa tan sinxela, o que implica moitas tecnoloxías profesionais. Por suposto, a maioría destes retos xa teñen solucións maduras. Primeiro de todo, necesitamos definir un sistema de diálogo de voz de "bo efecto". Creo que debería acadar os seguintes puntos:
(1) Baixa latencia. Só cunha baixa latencia as dúas partes na chamada poden ter unha forte sensación de tempo real. Por suposto, isto depende principalmente da velocidade da rede e da distancia entre as localizacións físicas das dúas partes na chamada. Desde a perspectiva do software puro, a posibilidade de optimización é moi pequena.
(2) Baixo ruído de fondo.
(3) O son é suave, sen a sensación de atascado ou pausa.
(4) Non hai resposta.
A continuación falaremos das tecnoloxías adicionais empregadas no sistema de diálogo de voz de rede real unha por unha.
1. Cancelación de eco AEC Case todos están afeitos a usar directamente a función de reprodución de voz do PC ou do portátil durante o chat de voz. Como todo o mundo sabe, este pequeno hábito supuxo un gran desafío para a tecnoloxía de voz. Cando se usa a función de altofalante, o son reproducido polo altofalante será recollido polo micrófono de novo e transmitido de volta á outra parte, para que a outra parte poida escoitar o seu propio eco. Polo tanto, nas aplicacións prácticas, é necesaria a función de cancelación do eco. Despois de obter o marco de audio recollido, este espazo antes da codificación é o momento para que funcione o módulo de cancelación de eco. O principio é simplemente que o módulo de cancelación de eco realiza algunhas operacións similares á cancelación no cadro de audio recollido segundo o cadro de son que acaba de reproducirse, para eliminar o eco do cadro recollido. Este proceso é bastante complicado e tamén está relacionado co tamaño da habitación na que estás cando conversas e coa túa situación na habitación, porque esta información determina a lonxitude da reflexión da onda sonora. O módulo de cancelación de eco intelixente pode axustar dinámicamente os parámetros internos para adaptarse mellor ao ambiente actual.
2. Supresión de ruído DENOISE A supresión de ruído, tamén coñecido como procesamento de redución de ruído, baséase nas características dos datos de voz para identificar a parte do ruído de fondo e filtrala dos cadros de audio. Moitos codificadores incorporan esta función.
3. JitterBuffer O búfer de jitter úsase para resolver o problema do jitter de rede. O chamado jitter de rede significa que o atraso da rede será cada vez maior. Neste caso, aínda que o remitente envíe paquetes de datos regularmente (por exemplo, envíase un paquete cada 100 ms), o receptor non pode recibir o mesmo tempo. Ás veces non se pode recibir ningún paquete nun ciclo e ás veces recíbense varios paquetes nun ciclo. Deste xeito, o son que escoita o receptor é unha tarxeta unha tarxeta. JitterBuffer funciona despois do descodificador e antes da reprodución de voz. É dicir, despois de completar a descodificación de voz, o cadro descodificado colócase no JitterBuffer e, cando chega a devolución de chamada da tarxeta de son, o cadro máis antigo recupérase do JitterBuffer para a súa reprodución. A profundidade do búfer de JitterBuffer depende do grao de jitter da rede. Canto maior sexa a fluctuación da rede, maior será a profundidade do búfer e maior será o atraso na reprodución de audio. Polo tanto, JitterBuffer usa un atraso maior a cambio dunha reprodución de son suave, porque en comparación co son unha tarxeta unha tarxeta, un atraso lixeiramente maior pero un efecto máis suave, a súa experiencia subxectiva é mellor. Por suposto, a profundidade do búfer de JitterBuffer non é constante, senón que se axusta dinámicamente segundo os cambios no grao de jitter da rede. Cando se restaure a rede para que sexa moi suave e sen obstáculos, a profundidade do búfer será moi pequena, polo que o aumento do atraso de reprodución debido a JitterBuffer será insignificante.
4. Detección de silencio VAD Nunha conversa de voz, se unha parte non fala, non se xerará tráfico. A detección de silencio utilízase para este propósito. A detección de silencio normalmente tamén está integrada no módulo de codificación. O algoritmo de detección silenciosa combinado co algoritmo anterior de supresión de ruído pode identificar se hai entrada de voz actualmente. Se non hai entrada de voz, pode codificar e emitir un marco codificado especial (por exemplo, a lonxitude é 0). Especialmente nunha videoconferencia de varias persoas, normalmente só unha persoa fala. Neste caso, o uso da tecnoloxía de detección silenciosa para aforrar ancho de banda aínda é moi considerable.
5. Algoritmo de mestura Nun chat de voz de varias persoas, necesitamos reproducir datos de voz de varias persoas ao mesmo tempo e a tarxeta de son só reproduce un búfer. Polo tanto, necesitamos mesturar varias voces nunha soa. Isto é o que fai o algoritmo de mestura. Mesmo se pode atopar un xeito de evitar a mestura e deixar reproducir varios sons ao mesmo tempo, co propósito de cancelar o eco, debe mesturarse nunha soa reprodución, se non, a cancelación do eco só pode eliminar algúns dos sons múltiples en a maioría. Todo o camiño. A mestura pódese facer no lado do cliente ou do servidor (o que pode aforrar ancho de banda descendente). Se se usan canles P2P, a mestura só se pode facer no lado do cliente. Se se mestura no cliente, normalmente, a mestura é o último elo antes de xogar. Este artigo é un resumo da nosa experiencia na implementación da parte de voz de OMCS. Aquí acabamos de facer unha sinxela descrición de cada ligazón da figura e calquera delas pode escribirse nun longo papel ou incluso nun libro. Polo tanto, este artigo é só para fornecer un mapa introdutorio para aqueles que son novos no desenvolvemento de sistemas de voz en rede e dar algunhas pistas.



|
|
|
|
Como distante (long) a tapa do transmisor?
A franxa de transmisión depende de moitos factores. A distancia real baséase na altura da antena de instalar, a ganancia da antena, usando ambiente como a construción e outras obturacións, a sensibilidade do receptor, a antena do receptor. Instalación de antena máis alta e usando o campo, a distancia vai moito máis lonxe.
EXEMPLO 5W FM Transmitter usar na cidade e cidade natal:
Teño un uso do cliente 5W transmisor FM EUA con antena GP na súa cidade natal, e proba-lo con un coche, cubrir 10km (6.21mile).
I probar o transmisor FM 5W con antena GP na miña cidade natal, que cobren aproximadamente 2km (1.24mile).
I probar o transmisor FM 5W con antena GP na cidade de Guangzhou, que abranguen aproximadamente única 300meter (984ft).
Abaixo amósanse ao descanso aproximado de diferentes transmisores de enerxía FM. (O intervalo é de diámetro)
0.1W ~ 5W Transmisor FM: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W Transmisor FM: 3KM ~ 10KM
80W ~ 500W Transmisor FM: 10KM ~ 30KM
500W ~ 1000W Transmisor FM: 30KM ~ 50KM
1KW ~ 2KW Transmisor FM: 50KM ~ 100KM
2KW ~ 5KW Transmisor FM: 100KM ~ 150KM
5KW ~ 10KW Transmisor FM: 150KM ~ 200KM
Como contactar connosco para o transmisor?
Chama-me + 8618078869184 OU
Enviar email me [protexido por correo electrónico]
1.How lonxe quere cubrir de diámetro?
2.How altura de torre ti?
3.Where es?
E imos dar-lle consellos máis profesional.
Sobre nós
FMUSER.ORG é unha empresa de integración de sistemas centrada en equipos de transmisión / transmisión de audio sen fíos de radio / estudio de vídeo e procesamento de datos. Estamos ofrecendo todo desde asesoramento e consultoría a través da integración de rack ata a instalación, posta en servizo e adestramento.
Ofrecemos transmisor de FM, transmisor de TV analóxico, transmisor de TV dixital, transmisor UHF de VHF, antenas, conectores de cable coaxial, STL, procesamento de aire, produtos de transmisión para o estudio, monitorización de sinais de RF, codificadores de RDS, procesadores de audio e unidades de control de sitios remotos. Produtos IPTV, codificador / decodificador de audio / vídeo, deseñados para satisfacer as necesidades de grandes redes de transmisión internacionais e pequenas estacións privadas.
A nosa solución ten estación de radio FM / estación de televisión analóxica / estación de TV dixital / equipos de estudio de vídeo e vídeo / enlace de transmisión de estudio / sistema de telemetría de transmisor / sistema de TV de hotel / transmisión en directo IPTV / transmisión en directo de transmisión / conferencia de vídeo / sistema de transmisión CATV.
Estamos a usar produtos de tecnoloxía avanzada para todos os sistemas, porque sabemos que a alta fiabilidade e alto rendemento son tan importantes para o sistema e a solución. Ao mesmo tempo, temos que asegurarnos que o noso sistema de produtos a un prezo moi razoable.
Temos clientes de radiodifusores públicos e comerciais, operadores de telecomunicacións e autoridades reguladoras, e tamén ofrecemos solucións e produtos a moitos centos de emisoras locais e comunitarias máis pequenas.
FMUSER.ORG leva máis de 15 anos exportando e ten clientes en todo o mundo. Con 13 anos de experiencia neste campo, temos un equipo profesional para resolver todo tipo de problemas do cliente. Dedicámonos a ofrecer prezos extremadamente razoables de produtos e servizos profesionais. Correo electrónico de contacto: [protexido por correo electrónico]
nosa fábrica

Temos modernización da fábrica. Estás convidado a visitar a nosa fábrica cando chegar a China.

Actualmente, xa existen clientes 1095 en todo o mundo visitan nosa oficina Guangzhou Tianhe. Se ve a China, está invitado a visitar-nos.
na Feira

Esta é a nosa participación en 2012 Global Sources Hong Kong Fair Electrónica . Clientes de todo o mundo finalmente ter a oportunidade de estar xuntos.
Onde está Fmuser?
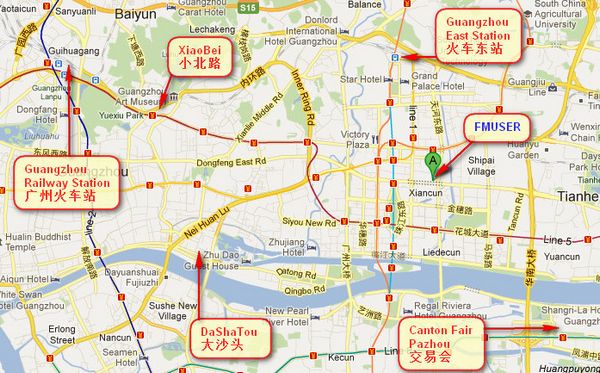
Podes buscar nestes números " 23.127460034623816,113.33224654197693 "en google map, entón podes atopar a nosa oficina fmuser.
oficina FMUSER Guangzhou está Tianhe District, que é a centro do cantón . moi preto ao Feira de Cantón , Estación ferroviaria Guangzhou, estrada Xiaobei e dashatou , Só ten minutos 10 tomar TAXI . Benvidos amigos de todo o mundo a visitar e negociar.
Contacto: Ceo azul
Móbil: + 8618078869184
WhatsApp: + 8618078869184
Wechat: + 8618078869184
E-mail: [protexido por correo electrónico]
QQ: 727926717
Skype: sky198710021
Dirección: No.305 cuarto Huilan Edificio No.273 Huanpu Estrada Guangzhou China Zip: 510620
|
|
|
|
Inglés: Aceptamos todos os pagos, como PayPal, tarxeta de crédito, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, Se tes algunha pregunta, póñase en contacto comigo [protexido por correo electrónico] ou WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Recomendamos que use Paypal para mercar os nosos produtos, PayPal é unha forma segura de mercar en internet.
Cada da nosa lista de elementos de páxina de fondo na parte superior ten un logotipo PayPal para pagar.
Tarxeta de crédito.Se non ten paypal, pero ten tarxeta de crédito, tamén se pode facer clic no botón amarelo PayPal para pagar coa súa tarxeta de crédito.
-------------------------------------------------- -------------------
Pero se non ten unha tarxeta de crédito e non ten unha conta PayPal ou de difícil ten un accout PayPal, pode utilizar o seguinte:
Western Union.  www.westernunion.com www.westernunion.com
Pago por Western Union para min:
Nome / nome: Yingfeng
Apelido / Apelido / Apelido: Zhang
Nome completo: Yingfeng Zhang
País: China
Cidade: Guangzhou
|
-------------------------------------------------- -------------------
T / T. pago por T / T (transferencia bancaria / transferencia telegráfica / Transferencia bancaria)
Primeira información bancaria (conta da empresa):
SWIFT BIC: BKCHHKHHXXX
Nome do banco: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Enderezo bancario: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
CÓDIGO BANCO: 012
Nome da conta: FMUSER INTERNATIONAL GROUP LIMITED
Conta NON. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Segunda INFORMACIÓN BANCARIA (CONTA DA EMPRESA):
Beneficiario: Fmuser International Group Inc.
Número de conta: 44050158090900000337
Banco do beneficiario: China Construction Bank Sucursal de Guangdong
Código SWIFT: PCBCCNBJGDX
Enderezo: estrada Tianhe NO.553, Cantón, Guangdong, distrito de Tianhe, China
** Nota: cando transfira cartos á nosa conta bancaria, NON escriba nada na área de comentarios, se non, non poderemos recibir o pago debido á política gobernamental sobre o comercio internacional.
|
|
|
|
* Será enviado en 1 2 día de traballo cando o pagamento clara.
* Nós imos envialo seu enderezo de paypal. Se queres cambiar de dirección, por favor, envíe o seu enderezo correcto e número de teléfono para o meu e-mail [protexido por correo electrónico]
* Se os paquetes está baixo 2kg, que serán enviados vía correo aéreo, vai levar preto de 15-25days para a súa man.
Se o paquete é máis que 2kg, nós enviamos vía EMS, DHL, UPS, FedEx entrega rápida expresa, vai levar preto de 7 ~ 15days para a súa man.
Se o paquete de máis de 100kg, enviarémoslle vía DHL ou transporte aéreo. Isto levará uns 3 ~ 7days para a súa man.
Todos os paquetes son a forma China Guangzhou.
* O paquete enviarase como un "agasallo" e descartarase o menos posible, o comprador non terá que pagar o "IMPOSTO".
* Despois de navío, nós enviarémosche un correo electrónico e darlle o número de rastreamento.
|
|
|
Para garantía.
Contacte connosco --- >> Devólvenos o artigo --- >> Reciba e envíe outro substituto.
Nome: Liu Xiaoxia
Dirección: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou China.
CEP: 510620
Teléfono: + 8618078869184
Por favor, retorne a este enderezo e escribir o seu paypal enderezo, nome, problema na nota: |
|













